- 강의
- 46강(컬렉션 List 만들기) ~ 48강(wrap-up)
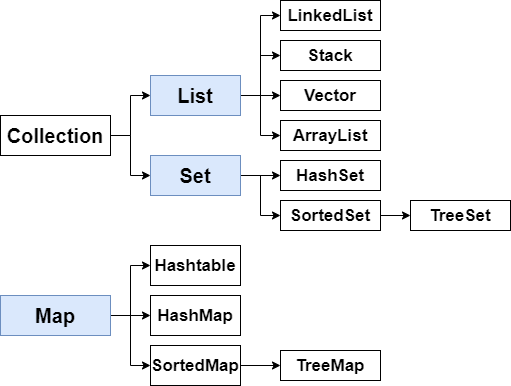
Collection
- collection framework
- java.util 패키지 내 존재
- Collection 인터페이스
- Map 인터페이스
- Structure
- Array 구조
- 연속적인 메모리 구조
- 인덱스를 이용해서 값 접근 속도가 빠름
- 새로운 데이터 공간을 할당해야 하기 때문에 데이터 추가 및 삭제 속도는 느림
- Node 구조
- 포인터를 이용해서 앞, 뒤 노드의 위치를 알 수 있음
- 포인터를 통해서 다음 값에 접근하기 때문에 값 접근 속도가 느림
- 포인터값만 변경하면 되기 때문에 데이터 추가 및 삭제 속도는 빠름
- 비교
| |
Array |
Node |
| 장점 |
- 빠른 접근 속도
- 메모리 공간 효율성 ↑ |
- 동적 크기 조정 가능 → 구조 변경 용이
- 빠른 삽입 및 삭제 |
| 단점 |
- 어려운 크기 조절
- 삽입 및 삭제 비용 ↑ |
- 링크 필드 참조로 접근해서 느린 접근 속도
- 포인터 사용으로 인한 메모리 추가 사용 |
List
- ArrayList
- Array 구조 기반
- 메서드
- add(값) : 값 추가
- add(index, 값) : index 위치에 값 추가
- get(index) : index 위치의 값 반환
- remove(index) : index 위치의 값 삭제
- size() : 크기 반환
- isEmpty() : 비어있으면 true, 값이 있으면 false 반환
- contains(값) : 값이 존재하면 treu, 없으면 false
- indexOf(값) : 값의 인덱스 반환, 없으면 -1 반환
- clear() : 값 전부 삭제
- LinekdList
- ArrayList와 LinkedList 속도 차이를 생각해서 구현하기 → 데이터가 많아질수록 성능이 크게 차이남
Set
- 순서와 중복이 없는 집합
- 종류
- HashSet : Array 구조 기반
- TreeSet : Node 구조 기반
- 메서드
- add(값) : 값 추가
- remove(값) : 값 제거
- contains(값) : 값이 존재하면 true, 없으면 false
- size() : 요소의 개수 반환
- isEmpty() : 요소가 있으면 true, 없으면 false
- clear() : 모든 요소 제거
Map
- key와 value들의 키쌍으로 이루어진 집합
- key는 중복되지 않음
- 종류
- HashMap : Array 구조 기반
- TreeMap : Node 구조 기반
- 메서드
- put(key, value) : 값 추가
- get(key) : 키에 해당하는 값 반환
- containsKye(key) : key가 있으면 true, 없으면 false
- remove(key) : 키-값 쌍의 삭제
- size() : 키-값 쌍의 개수
- keySet() : 키들을 Set 타입으로 반환
Hash
- 임의의 고정된 크기의 데이터를 고유한 값으로 변환하는 함수
- 용도
- 데이터 무결성 검사
- 데이터 암호화
- 데이터 검색
- Hash 실습 코드
public class Main {
public static String hashString(String input) {
try {
// MessageDigest 인스턴스 생성 (해시 알고리즘으로 SHA-256 선택)
MessageDigest digest = MessageDigest.getInstance("SHA-256");
// 입력 문자열을 바이트 배열로 변환하여 해시 함수에 전달
byte[] hashBytes = digest.digest(input.getBytes(StandardCharsets.UTF_8));
// Base64로 인코딩하여 해시된 문자열 반환
return Base64.getEncoder().encodeToString(hashBytes);
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
return null;
}
}
public static void main(String[] args) {
// 암호화
String pw = "abc";
String hashPw = hasString(pw); // 고유한 값, 암호화값
// 데이터 검색
long hashCode = Object.hashCode(pw); // 고유한 정수값으로 변환됨
}
}
- 동작 과정
- 코드실행
- 객체의 hashCode() 호출
- 해쉬값의 절대값을 Array 구조 size로 % 적용해서 array의 index 구함
- array[index] 위치에 값 저장 or 조회
- 동작과정 예시 (Array 구조 크기 : 10)
- HashMap의 put()
- map.put("abc", 100);
- "abc".hashCode() = 102394
- abs(102394) % 10 = 4
- array[4] = { key : "abc", value : 100 } 저장
- HashMap의 get()
- map.get("abc");
- "abc".hashCode() = 102394
- abs(102394) % 10 = 4
- array[4] = { key : "abc", value : 100 } 반환
- HashSet의 add()
- set.add("abc");
- "abc".hashCode() = 102394
- abs(102394) % 10 = 4
- array[4] = { "abc" }
- HashSet의 add() - 중복된 값을 넣는 경우
- set.add("abc");
- "abc".hashCode() = 102394
- abs(102394) % 10 = 4
- array[4]에 이미 값이 있으므로 값 저장 X
Tree
- BST 자료 구조 사용(Binary Search Tree)