📄 학습내용
열거형(Enum)
- 열거형(Enum, Enumerated Type) : 상수들을 선언한 집합
- 특징
- final 키워드 사용 가능
- switch문에서 사용 가능
- 장점
- 편리하게 상수 선언 및 관리
- 상수명 중복 방지
- 타입에 대한 안전성 보장
- 선언
- 관례적으로 상수명은 대문자로 작성
- 자동적으로 정수값이 0부터 할당
enum 열거형_이름 {
상수명1, // 정수 0 할당
상수명2, // 정수 1 할당
상수명3, // 정수 2 할당
...
}// 열거형 선언 예시
enum Week {
MONDAY,
TUESDAY,
WEDNESDAY,
THURSDAY,
FRIDAY
}- 선언
- 열거형_이름.상수명
- 열거형_참조변수 참조변수명 = 열거형_이름.상수명;
public class Test {
public static void main(String[] args) {
Week monday = Week.MONDAY;
System.out.println(monday);
System.out.println(Week.TUESDAY);
}
}
// 출력결과
MONDAY
TUESDAY- java.lang.Enum 메서드 : Object에 정의된 메서드와 동일
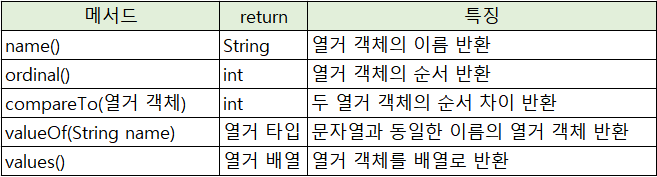
enum Week {
MONDAY,
TUESDAY,
WEDNESDAY,
THURSDAY,
FRIDAY
}
public class Package {
public static void main(String[] args) {
Week monday = Week.MONDAY;
System.out.println(monday);
System.out.println(Week.TUESDAY);
System.out.println(Week.valueOf("WEDNESDAY"));
System.out.println(Week.THURSDAY.name() + " : " + Week.THURSDAY.ordinal());
System.out.println(Week.FRIDAY.compareTo(monday)); // MONDAY 상수 : 0, FRIDAY 상수 : 4
System.out.println(Arrays.toString(Week.values()));
}
}
// 출력 결과
MONDAY
TUESDAY
WEDNESDAY
THURSDAY : 3
4
[MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY]
제네릭(Generic)
- 제네릭(Generic) : 변수 타입을 일반화해서 추후에 설정할 수 있도록 하는 것
- 특징
- 하나의 클래스를 통해서 다양한 타입의 데이터의 인스턴스 생성 가능
- <T> : T는 제네릭 문법
- 필요성
- 타입 별로 클래스를 선언해서 사용하는 것은 비효율
- 제네릭 클래스
- 제네릭이 사용된 클래스
- 타입 매개변수 : <> 안에 매개변수의 타입을 추후에 작성할 수 있도록 하는 제네릭 문법, 다양한 형태로 선언 가능
- T : Type
- K : Key
- V : Value
- E : Element
- N : Number
- R : Result
- 특징
- static이 붙은 클래스 변수나 클래스 메서드에서 사용 불가능
- 사용 시 타입 매개변수에 치환될 타입으로 기본 타입 사용 불가능 → 래퍼 클래스 사용
- 선언 및 초기화
// 제네릭 클래스 선언
class 클래스명<타입_매개변수> {
...
}
// 제네릭 클래스
클래스명<데이터_타입> 참조변수 = new 클래스명<데이터_타입>(생성자);
클래스명<데이터_타입> 참조변수 = new 클래스명<>(생성자); // 구체적인 타입 생략 가능// 제네릭 클래스 선언
class Generic<T> {
private T var;
public T method(T var) {
this.var = var;
System.out.println(this.var);
return this.var;
}
}
public class Package {
public static void main(String[] args) {
// 제네릭 클래스 생성
Generic<Integer> generic1 = new Generic<Integer>();
Generic<String> generic2 = new Generic<>();
generic1.method(100);
generic2.method("String!!");
}
}
- 제한된 제네릭 클래스
- 타입 매개변수으로 선언할 수 있는 한계가 지정된 제네릭 클래스
- 경우
- 특정 클래스 또는 하위 클래스 타입 지정
- 정해진 인터페이스를 구현한 클래스 타입 지정
- 특정 클래스 상속 및 특정 인터페이스를 구현한 클래스 타입을 동시에 지정
- 위치 : 클래스 & 인터페이스
- 선언 : 인터페이스나 클래스 상관없이 extends 키워드 이용
class 클래스명<T extends 클래스명> { ... }
class 클래스명<T extends 인터페이스명> { ... }
class 클래스명<T extends 클래스명 & 인터페이스명> { ... }
- 제한된 메서드
- 제네릭을 선언한 메서드
- 제네릭 메서드의 타입 매개변수 != 제네릭 클래스의 타입 매개변수 같은 제네릭 문법을 써도 별개의 것!
- 이유 : 타입이 정해지는 시점이 다르기 때문
제네릭 클래스의 타입이 정해지는 시점 - 클래스가 인스턴스화할 때
제네릭 메서드의 타입이 정해지는 시점 - 메서드가 호출될 때
- 이유 : 타입이 정해지는 시점이 다르기 때문
- 와일드카드
- 어떤 타입이든 상관없이 대체 가능한 타입 파라미터
- 기호 : ?
- 키워드 조합
- 상한 제한 : <? extends 클래스> → 같은 클래스 또는 하위 클래스만 허용
- 하한 제한 : <? super 클래스> → 같은 클래스 또는 상위 클래스만 허용
- 기본값(extends와 super 키워드 사용하지 않은 경우) : <?> 의미 = <? extends Object>
래퍼 클래스
- 기본 타입의 데이터를 개체로 취급할 수 있도록 하는 클래스
| 기본타입 | int | char | byte | short | long | float | double | boolean |
| 래퍼 클래스 | Integer | Character | Byte | Short | Long | Float | Double | Boolean |
예외 처리(Exception Handling)
- 예외 처리(Exception Handling) : 예외가 발생했을 경우에 강제 종료가 아닌 정상적으로 프로그램이 진행될 수 있도록 처리하는 작업
- 예외 발생 요일
- 외부요인 : ex) 하드웨어 문제, 네트워크 연결 문제 등
- 내부요인
- 컴파일 에러(신택스 에러, Systax Errors) : 컴파일러가 발견하는 에러
- 런타임 에러 : 런타임(실행)할 때 JVM에서 발생하는 에러
- 에러와 예외
- 에러(error) : 복구가 어려운 정도의 오류
- 예외(exception) : 코드 수정을 통해서 복구할 수 있을 정도의 오류
- 예외 클래스
- Runtime Exception 클래스(unchecked 예외) : 컴파일어가 예외 처리 코드 여부 검사 X
- Other Exception 클래스(checked 예외) : 컴파일러가 코드 실행 전 코드 여부 검사
- 예외 객체(Exception e)로부터 정보 읽기
- e.getMassge() : 예외 원인 출력
- e.toString() : 예외의 내용과 원인 출력
- e.printStackTrace() : 단계별로 예외 출력(상세히)

- 예외 처리 방법
- try-catch문
- try문 : 예외가 발생할 것 같은 코드를 작성
- catch문 : 예외가 발생하면 예외 처리를 처리하는 코드 작성
- finally문 : 예외 처리와 상관없이 항상 동작되는 코드 작성(생략가능)
- 예외 전가
- 메서드를 정의할 때 발생할 것 같은 예외를 선언하고, 예외 처리를 함수 호출한 곳에서 처리할 수 있도록 예외를 회피하는 방법
- throws : 메서드명 뒤에 thorws를 선언해서 발생할 것 같은 예외 작성, 이때 함수가 호출한 곳에서 예외가 발생하면 호출한 곳에서 예외 처리
- try-catch문과 함께 사용해서 예외 전가된 메서드 호출 시 발생하는 예외 처리
- throws 키워드와 throw 키워드
- throws 키워드 : 예외 전가를 하기 위해서 메서드를 정의할 때 발생할 것 같은 예외를 선언하기 위해서 사용
- throw 키워드 : 예외를 의도적으로 발생시키는 메서드
- throw new 예외클래스();
- try-catch문
컬렉션 프레임워크

- 컬렉션 : 데이터를 그룹으로 묶은 것
- 컬렉션 프레임워크
- 컬렉션을 구현한 메서드와 인터페이스의 집합
- 데이터 추가, 삭제, 수정, 검색 등의 동작에 필요한 메서드와 인터페이스 제공
- 컬렉션 프레임워크의 핵심 인터페이스
| 인터페이스 | 데이터 순서 유지 | 중복저장 |
| List | O | O |
| Set | X | X |
| Map | X | 키 X 값 O |
- Collection 인터페이스 메서드
| 메서드 | 리턴 | 특징 |
| add(Object o) addAll(Collection c) |
boolean | 객체 추가 |
| contains(Object o) containsAll(Collection c) |
boolean | 객체가 있으면 true 반환 |
| isEmpty() | boolean | 비어있으면 true |
| equals(Object o) | boolean | 동일한 객체이면 true 반환 |
| remove(Object o) removeAll(Collection c) |
boolean | 객체 삭제 |
| retainAll(Collection c) | boolean | 객체 c 이외의 모든 객체 삭제 |
| iterator() | iterator | iterator 반환 |
| size() | int | 객체 수 반환 |
| clear() | void | 모든 객체 삭제 |
| toArray() | Object[] | 객체들을 객체배열(Object[])로 반환 |
| toArray(Object[] a) | Object[] | 객체들을 배열로 반환 |
Iterator
- Iterator : Collection 인터페이스에 선언된 함수 iterator()를 통해서 컬렉션의 요소를 읽어오는 타입(반복자)
- 메서드
- hasNext() : 다음 객체가 남아있으면 true, 아니면 false 반환
- next() : 컬렉션의 객체 하나 읽어오기
- remove() : next()로 읽은 객체 삭제
List

- List 인터페이스 : 인덱스가 부여되어 배열처럼 나란히 있는 구조
- List 인터페이스 메서드
| 메서드 | 리턴 | 특징 |
| add(int index, Object element) | void | 객체 추가 |
| addAll(int index, Collection c) | boolean | 컬렌션 추가 |
| set(int index, Object element) | Object | 객체 수정 |
| get(int index) | Object | 객체 반환 |
| indexOf(Object o) lastIndexOf(Object o) |
int | 순방향으로 객체 index 반환 역방향으로 객체 index 반환 |
| listIterator() listIterator(int index) |
ListIterator | List 객체를 탐색할 수 있는 ListIterator 반환 index부터 List 객체를 탐색할 수 있는 ListIterator 반환 |
| subList(int from, int to) |
List | from부터 to까지 부분 List 반환 |
| sort(Comparator c) | void | 비교자를 기준으로 list 정렬 |
| remove(int index) | Object | index에 있는 객체 삭제 |
| remove(Object o) | boolean | 객체 삭제 |
- ArrayList
- Vector 클래스를 개선한 클래스
- 특징
- index로 객체 관리
- 자동으로 저쟝용량 관리
- 연속적인 데이터
- 삭제 및 추가 시 데이터 이동하기 위해서 복사가 이루어짐
- 선언
ArrayList<타입_매개변수> 참조변수 = new ArrayList<타입_매개변수>(초기값);
ArrayList<타입_매개변수> 참조변수 = new ArrayList<>(초기값); // 생성자의 타입 매개변수 생략 가능
- LinkedList
- 효율적으로 데이터를 추가, 삭제하기 위해 사용되는 클래스
- 특징
- 이전 노드위치, 다음 노드위치, 값으로 이루어진 node(노드)로 구성
- 데이터 추가 및 삭제 시 노드의 위치값만 변경
- 선언
LinkedList<타입_매개변수> 참조변수 = new LinkedList<타입_매개변수>(초기값);
LinkedList<타입_매개변수> 참조변수 = new LinkedList<>(초기값); // 생성자의 타입 매개변수 생략 가능
- ArrayList와 LinkedList 비교
- ArrayList 사용 경우 : 객체 검색 및 출력이 많이 일어나는 경우
- LinkedList 사용 경우 : 객체 삭제 및 삭제가 많이 일어나는 경우
| 강점 | 약점 | |
| ArrayList |
|
|
| LinkedList |
|
|
Set
- Set 인터페이스 : 요소 중복 허용하지 않고 저장 순서 유지하지 않는 구조
- Set 인터페이스 메서드
| 메서드 | 리턴 | 특징 |
| add(Object element) | boolean | 객체 추가(중복된 객체면 false 반환) |
| contains(Object o) | boolean | 객체 검색(있으면 true 반환) |
| isEmpty() | boolean | 빈 객체인지 검사(비어 있으면 true 반환) |
| iterator() | iterator | 반복자 리턴 |
| size() | int | 객체수 |
| clear() | void | 모든 객체 삭제 |
| remove(Object o) | boolean | 객체 삭제 |
- HashSet
- 해시코드를 통해서 중복된 값을 허용하지 않고 저장 순서가 유지되지 않는 구조를 가지는 클래스
- 해시코드(hash code)란?
- 객체 해시코드란 객체를 식별하는 하나의 정수값
- Object의 hashCode() 메서드는 객체의 메모리 번지를 이용해서 해시코드를 만들어서 반환 → 객체 마다 다른 값을 가짐
- 선언
HashSet<타입_매개변수> 참조변수 = new HashSet<타입_매개변수>(초기값);
HashSet<타입_매개변수> 참조변수 = new HashSet<>(초기값); // 생성자의 타입 매개변수 생략 가능
- TreeSet
- 이진 탐색 트리 형태로 데이터 중복 저장을 허용하지 않고 저장 순서가 유지되지 않는 구조를 가지는 클래스
- 이진 탐색 트리(binary search tree)란?
- 정렬과 검색에 특화된 트리형태의 자료구조
- 최상위 노드 : 루트(root)
- 왼쪽 자식 노드의 값 < 루트(root)의 값 < 오른쪽 노드의 값
- 오름차순(기본 정렬방식)
- 메서드
- lower(Object o) : 객체 o를 제외한 객체들 중 가장 큰 값
- floor(Object o) : 객체 o를 포함한 객체들 중 가장 큰 값
- higher(Object o) : 객체 o를 제외한 객체들 중 가장 작은 값
- ceiling(Object o) : 객체 o를 포함한 객체들 중 가장 작은 값
- subSet(Object from, boolean fromclusive, Object to, boolean toclusive) : from부터 to까지 범위 지정
- 복사가 되는 것이 아니라 같은 treeset 객체를 공유
- 선언
TreeSet<타입_매개변수> 참조변수 = new TreeSet<타입_매개변수>(초기값);
TreeSet<타입_매개변수> 참조변수 = new TreeSet<>(초기값); // 생성자의 타입 매개변수 생략 가능
Map

- Map 인터페이스 : Entry 객체(key와 value)로 구성된 구조
- 키(key, 식별자) 중복 X, 값(value) 중복 O
- 같은 키로 저장하려면 값이 대체됨
- Map 인터페이스의 메서드
| 메서드 | 리턴 | 특징 |
| put(Object key, Object value) | Object | 객체 추가 새로운 키 → null 반환 동일한 키 → 대체되기 전의 값 반환 |
| containsKey(Object key) | boolean | 키 검색(키가 있으면 true 반환) |
| containsValue(Object value) | boolean | 값 검색(값키가 있으면 true 반환) |
| isEmpty() | boolean | 빈 객체인지 검사(비어 있으면 true 반환) |
| entrySet() | Set | entry(키와 값 쌍)인 모든 Map.Entry 객체를 Set 형태로 반환 |
| KeySet() | Set | 모든 키 객체를 Set 형태로 반환 |
| valuse() | Collection | 모든 값을 Collection 형태로 반환 |
| get(Object key) | Object | 키의 값 반환 |
| size() | int | 객체수 |
| clear() | void | 모든 객체 삭제 |
| remove(Object key) | Object | 키와 일치하는 entry 객체 삭제하고 키의 값 반환 |
- HashMap
- 해시 함수를 통해서 키와 값이 저장되는 위치를 결정해서 데이터를 저장하는 구조
- 특징
- 삽입되는 순서와 위치의 관련성 X
- 삽입되는 순서와 위치는 알 수 없음
- 데이터 검색에 뛰어난 성능을 가짐
- 키와 값의 타입을 따로 설정 가능
- Map.Entry 인터페이스 메서드
| 메서드 | 리턴 | 특징 |
| equals(Object o) | boolean | 동일한 Entry 객체 비교(같으면 true 반환) |
| getKey() | Object | Entry 객체의 key 객체 반환 |
| getValue() | Object | Entry 객체의 value 객체 반환 |
| setValue(Object value) | Object | value 변경 |
| hashCode() | int | Entry 객체의 해시코드 반환 |
- HashMap 순회하는 방법
- key 요소 이용
- entry 객체 이용
// HashMap 생성
HashMap<String, Integer> map = new HashMap<>();
// Entry 객체 저장
map.put("key1", 1);
map.put("key2", 2);
map.put("key3", 3);
// HashMap 순회하는 방법 1) key 요소 이용
Set<String> keySet = map.keySet();
Iterator<String> keyIterator = keySet.iterator(); // 반복자 이용
while(keyIterator.hasNext()) {
String key = keyIterator.next();
Integer value = map.get(key);
System.out.println(key + " : " + value);
}
// HashMap 순회하는 방법 2) entry 객체 이용
Set<Map.Entry<String, Integer>> entrySet = map.entrySet();
Iterator<Map.Entry<String, Integer>> entryIterator = entrySet.iterator(); // 반복자 이용
while(entryIterator.hasNext()) {
Map.Entry<String, Integer> entry = entryIterator.next();
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println(key + " : " + value);
}- HashTable
- HashMap와 사용방법이 유사하고 동일한 내부 구조를 가지는 클래스
⭐ 공부 난이도
열거형, 제네릭 ☆☆☆☆★
예외처리 ☆☆★★★
컬렉션 ☆☆☆★★
🌕 느낀점
코드 스테이츠를 시작한지 거의 한 달이 다 되어가는데, 드디어 제대로 된 공부를 한 느낌이었다. 자료구조를 어느 정도 알고 있어서 그런지 자료구조 관련 내용이 나와도 이해하기 수월했다. 예상치도 못하게 예외처리에서 예외 전가(throws)를 이해하는데 상당한 시간이 걸렸다. 코드 스테이츠 글만으로는 이해되지 않아서 다른 사이트를 참고해서 겨우겨우 이해할 수 있었다. 처음에는 예외를 함수가 호출한 곳에서 처리한다는 의미와 throws를 쓰는 의미를 이해하지 못했는데 이제 잉해할 수 있게 되었다. 그리고 C++과 다르게 자료구조를 사용할 수 있는 컬렉션 프레임워크가 잘 구현되어 있어서 나중에 코딩 테스트를 준비할 때 자바를 사용해도 괜찮아보였다. 물론 파이썬이 자료구조 쪽으로는 더 특화되어 있어서 편리하겠지만... 이건 급한 것은 아니니까 코테 준비할 때 정하기로 하자 생각보다 양이 많아서 처음으로 학습 내용을 6시 전에 끝내지 못했다. 내일 페어 활동을 하고 남는 시간에 블로그 정리를 해야겠다.
'코드스테이츠 - 3회차 백엔드 부트캠프 > Section 1' 카테고리의 다른 글
| 2022.09.15 목 - 애너테이션, 람다, 스트림, 파일 입출력 (0) | 2022.09.15 |
|---|---|
| 2022.09.14 수 - 컬렉션 문제 풀기 (0) | 2022.09.14 |
| 2022.09.08 목 - 프로그램 작성 (0) | 2022.09.08 |
| 2022.09.07 수 - 다형성, 추상화 (0) | 2022.09.07 |
| 2022.09.06 화 - 상속, 캡슐화 (0) | 2022.09.06 |